Final Thoughts
Taking a “Shift Left” approach from the top-down is also a good idea – it allows teams to be more unified from the start, so that testers, business analysts, and developers are not playing telephone regarding what they need from each other. Realistically however, shifting left should occur on all levels, and it would make sense for organizations to meet at the middle regarding how to implement such a strategy.
It takes the leaders of an organization, the directors of technology, QA heads and leads, heads of product, to put forth a plan like this and get their teams to buy into a philosophy of being more agile and working together more frequently. It then is up to these smaller agile teams to make sure their actual work is modular and readable, following some of the concepts we have discussed above, to implement the vision of their leaders.
From there, every organization will have its own unique needs, for example, maybe some legacy application testing teams will remain more siloed from their peers, or perhaps over-modularizing one’s test code might not be so fruitful if one’s application is undergoing changes at a very high rate.
Regardless, we see the trend of shifting left as being a way of the future as to how teams work, given the direction of where technology is headed today.
Here at SmartBear, we believe that combining the high-level philosophy of Agile-style development and testing, with the lower level efforts of Object-Oriented programming and modularity, can certainly pave the road for organizations to find fewer defects overall in their applications, allowing them to spend less time on defect maintenance, along with saving them time on the defects they do have to fix as well.
With tools like SmartBear’s TestLeft and HipTest, companies can meet the demand for outputting quality software at a high rate, while still growing their business financially.
Introduction
As the Software Testing Industry move from more sequential-based testing methods to a more agile type of development and testing process, it has become necessary to not only employ a larger and more technical base into one’s testing efforts, but to also adopt said base’s penchant for solving problems in a specific way; that way being a more modular-based testing approach, one that can be described by the popular development method, Object-Oriented Programming (OOP).
The idea, at a high level, is to attack problems by dividing them into smaller sub-problems, allowing testers to make their problems more manageable, as well as allowing users to build more complex testing architecture out of these modular “pieces”.
One can then reuse any modular development or testing “piece” in any other use cases that require them, and then, considering that these modular “pieces” ought to be as small as can possibly be, said pieces will then be easier to fix and maintain at a unit level, andsubsequently at a system level as well.
These ideas form the core of Objected-Oriented Programming and Design and can be used to implement a successful testing framework, in addition to supporting the “Shifting Left” of testing organizations across any industry.
Why we want to Shift Testing Left
The idea of “Shift Left” is a simple one: move one’s focus on finding errors and faults in their application(s) earlier in the development cycle. Instead of testing in silos, in separate teams, the point is to pursue a larger effort in a testing approach that involves more parties in one’s organization, with the main goal being to reduce the time it takes to fix applications bugs, ensure quality and reduce the risk of failure as an application is deployed, and of course, save testing and operating costs down the line.
The above sounds a lot like an Agile development and testing methodology, and that is exactly what it is, so this idea isn’t exactly novel in the testing space. But, we are seeing a movement towards this idea, as teams and organizations looking to be more agile in their processes are now looking for toolsets and strategies that will help the employ the above, for the reasons I will elaborate on below.
As we can see from the graph above, IBM’s research shows us that most organizations are finding bugs later in the development process, where discovering and subsequently fixing bugs can be an expensive process. Bugs found by a siloed QA team will have to be send upstream to the Development team, who then will have to refocus away from their main task, which is the outright development of the application in question, and work on fixing the found bugs.
In general, this will further add time to not only the development process, but then also the QA process as well, as testers will have to retest the errors found, along with running regression and working on finding any other bugs. We see this issue plague development teams, as they then must push out the deployment of their release depending on the severity of the errors found.
We also see pain in the form of ensuring quality in the application being built; if teams are working separately regarding the health of their application, it would be more likely that errors will pop up and worsen the performance of the application, and errors that could have been found by a developer might be harder to root out by a tester with less intimate knowledge of the code under test.
Furthermore, many QA teams feature a less technical staff than that of a Development team, and thus we see the process of finding bugs post-development becomes a much more arduous task than it needs to be, with teams not reusing tests from Development, or teams missing knowledge on errors that another team might be aware of, along with having perhaps a more non-technical grouping of people attack errors that are quite technical in nature.
One’s risk of application failure is naturally higher due to these circumstances.
At the end of the day though, the above two factors that bog down testing, namely the time spent identifying bugs, sending them back to Development and back, and then the breakdown of quality due to a lack of connectivity between QA and Development teams, both contribute to the problem we all care about: the rising financial costs of ensuring technical and functional quality.
The graph from earlier in this section demonstrates this point effectively – it literally is more expensive to find a bug during production than it would be to find a bug earlier, let’s say right during the development phase of an application.
A bug found in production could cause in increase in renewal churn, along with perhaps jeopardizing deals for a sales team. Even the time spent in finding and fixing bugs is directly correlated with the cost of repair – how many extra man hours would a QA and Development team spend in fixing bugs found late in the development cycle?
And if, on average, there exists more bugs due to the disparate nature of a QA and Development team, then as mentioned before, one is setting back their teams days or weeks, which will certainly drive up operating costs for an organization.
To put it simply, more bugs + bugs discovered post-development = a significant rise in costs for the organization, and this very fact is exactly why organizations looking to mitigate the above equation and lower their operating costs look toward this “Shift Left” movement as the answer to their problems.
Object-Oriented Programming
Objected-Oriented Programming is a coding paradigm that uses the concepts of “objects”, which is simply a container that can hold both data, which would be in the form of a field (often known as a member variable or data member), and code, meaning procedures, in the form of methods (functions).
In general, an object can have procedures and methods that can access and perhaps modify any data fields that are native to said object, and thus one uses these procedures and features to allow objects to hold, manipulate, and share any data between other structures that may need it, including other objects.
In fact, that’s the idea of Object-Oriented Programming: the building of programs through objects that interact with one another.
here are many types of Objected-Oriented Programming languages, although the most popular ones in use would be those that are “class-based”, meaning that any object in the program is an instance of a “class”. A “class”, in this case, would be the abstract definition of an object – it will have member variables and methods, but the member variables might not hold any data until initialized, which one would do by declaring an instance of the class as an object in their code.
Thus, one can declare objects of the same class type to be different in terms of the data they hold – class instantiations can even have a different look and feel depending on how one initializes their class instance (object), allowing one to manipulate these data structures to fit their purposes more exactly.
Popular class-based Object-Oriented Programming languages in use are Java, C++, C#, Python, Ruby, Swift, PHP, and Smalltalk, among others.
These languages can be used for other programming strategies, such as Procedural or Prototype-based programming, and sometimes these paradigms are used concurrently as well – that being said, we will focus on Object-Oriented programming in this whitepaper, and how we can leverage it to properly “shift left” in our testing activities.
How does OOO fit into and promote Shifting Left?
So, now that we have discussed the concept of Shifting Left, and its value to be had for an organization developing and testing applications, how do Object-Oriented Programming concepts fit into this idea? Well, this is where we get to see how this Shift Left movement can actually be implemented by the teams it is designed to help.
We can use the main concept of Object-Oriented Programming, namely the idea of breaking down problems into smaller sub-problems, in conjunction with Shifting Left, to not only tackle problems in a more swift and agile format, but also to apply these practices to the test architecture and associated code a team would develop in this scenario.
Below, I will outline how being modular at a code and process level will then provide a larger enterprise value across one’s organization.
Readability and Modularity
An important trait that developers strive for when writing code is that it is readable, not only for other developers in their team, but perhaps for people who are not familiar with the code or project at all.
The idea is that readable code is easier to navigate through for a new tester/developer, as well as then being easier to edit and fix as well. Using Object-Oriented coding practices is a much cleaner and easier to follow way of building out a testing framework, then to, let’s say, have a more disparate system of files and scripts one would use to build their architecture.
Using classes adds easy to follow hierarchy between the types of tests or scenarios one would want use, and the class, at least in Object-Oriented Programming, would have all the necessary parts for a test scenario or set of scenarios to run: any data, initialization methods, teardown methods, event or except handlers, etc.
Thus, the class can act as a nice unit for us to make sure that a certain component is working in full, and then we can add these classes, or units, together to create a larger test scenario.
Then, at the code level, using a class-based structure will make the amount of code needed to be written shorter. I could instantiate, for example, an instance of a textbox on a web application I want to interact with, using several lines of code, as we see below:

Here, we are using one of SmartBear’s solutions, TestLeft, to generate this instance for us (I will touch on that product later!), but if we were to use an open source tool, for example, we would have to script this out manually. Now, I may need to generate a specific instance of a textbox or another control, but if I have to do this continually across my test cases, then my code will be a lot less readable down the line.
We see this problem occur often with users of open source web testing tools, for example, as building out a page object model is an arduous task, and so users would rather script out the instance directly.
A page object model, however, would be far more useful in building a more robust test long-term; in the image below, we have a method representing the same object that is in the above image, but as you can see, we now have a method that can easily return to us out textbox, all in a one-line call in code.
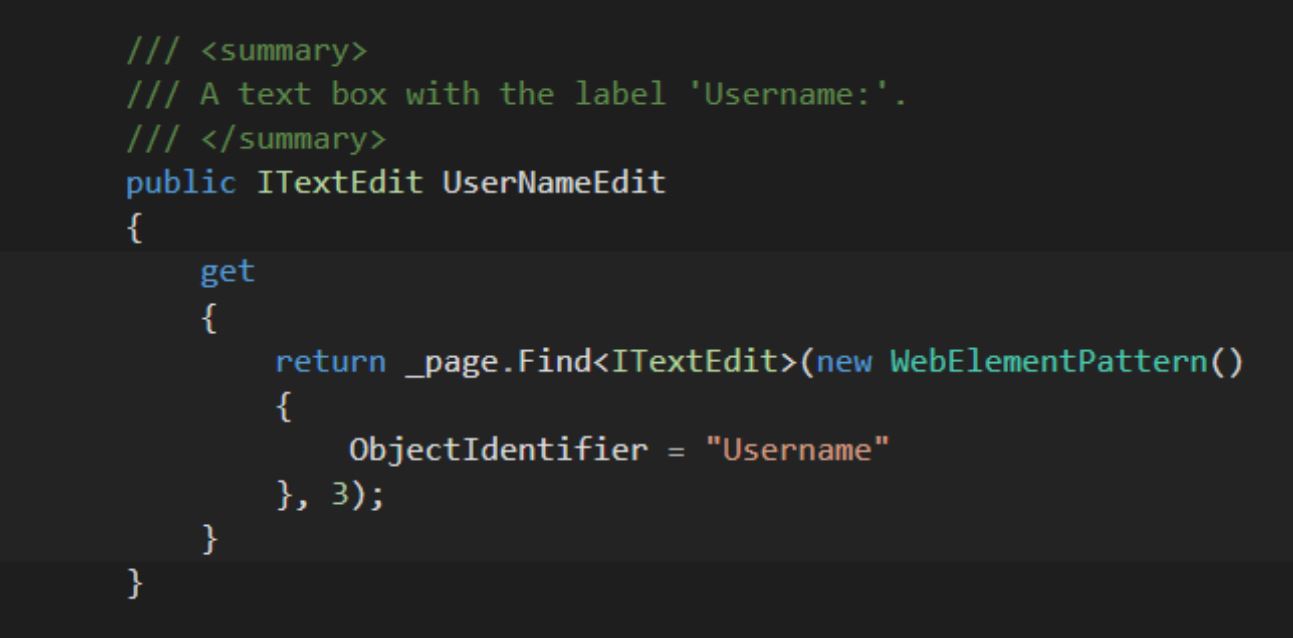
TestLeft also generated for us this above method, and can be used by testers and developers to create page object models in a few clicks – we can record all the parent objects as classes, and then what that allows us to do is call our objects, like this textbox, in easy to read one-line snippets of code, as opposed to eleven lines plus of code.

It would be good practice to develop a page object model even if using an open source tool, for the reasons stated above, but users have a hard time doing this consistently, given the size of their applications under test.
That’s where a tool like TestLeft can come in and give us modularity right out the box, giving us cleaner and more readable code pieces to work with. From there, our tests, leveraging the power of this model and Object-Oriented Programming, can be written not only faster, but written with way less code, and in a format where every step in a test, for the most part, can be represented by a single line of code.
Creating code that is readable will not only allow users to navigate code easier, regardless of skill level, but it will also allow users to more easily reuse these modular components in other test scenarios as well.
Maintenance and Testing Health
My last point in discussing Object-Oriented Programming practices as a mechanism to aid organizations in “Shifting Left” is the end goal of this shift: to create a testing structure that will stand the test of time and change – as time passes, applications under test may become more complex, and would change in terms of their underlying code, to say the least.
Thus, building a testing base that is both modular in design (classes, subclasses, and methods to represent one’s application, for example), and from there, readable in its construction (code that is commented, properly indented, architecture that has well-written READMES, etc.) will make it much easier for testers and developers to fix and update this base.
It will always be easier to fix code that does less, i.e. methods that do one thing as opposed to several things, will always be easier to maintain, as there is only one action, hypothetically speaking, that a tester or developer would have to look for, in case of error.
So, by building an architecture out of pieces, methods that “do one thing”, and so on, testers will spend less time fixing these individual components if they were to break. Add in comments and a defined organizational structure around these pieces, and it will be quicker for testers to find a broken piece, or trace through a call stack looking for an error, versus trying to analyze a “piece” that could do one of several actions.
As mentioned earlier, a lot of these values do play into each other, but in my opinion, that’s what makes this approach so powerful – if one is organized at the lowest possible level of a project’s implementation (the code), then those good practices will flow up when testers and developers are building and testing larger components and applications that they have built from smaller modular ones.
Making testing code that is easier to read and faster to fix will ensure a more consistent quality of code as well, especially if testers and developers are working with an Agile mindset. And again, saved time, along with a lower risk of failures and a lower number of bugs in general will equal much lower operating costs for any organization, which, even outside of shifting left, is a goal for every organization out there.
Reusability
Reusable code is code that is both readable and modular, and if we go with the aforementioned strategies in this paper, then we can achieve these standards fairly easily. Developers can share a page object model around with their peers, especially one that is commented and properly organized. Other developers and testers can then use said model’s objects in their own tests, allowing all users to work from a unified set of resources.
The practices can certainly speed up workflow, as teams will spend less time ramping themselves up on the work of their team members, as well as subsequently being able to more rapidly implement tests against this shared work.
A lot of these values are born out of each other, but that’s what happens when teams work to optimize their organizational. With practices based in modularity, teams will spend even less time creating or recreating test scenarios, code snippets, models, as not only will users share work as I pointed out before, but users can build even more complex automated tests from the smaller parts that they build.
That’s the beauty of modularity – objects and pieces can easily be combined to create larger pieces, simplifying the demands of building a testing framework and surrounding architecture.
Less time spent = less operating costs for the business, which I think is an equation that everyone can agree to be of value. And if one’s architecture relies on small, modular, but sound components to construct it, then we see a sizable effect on the long-term health of said architecture.
