
Introduction
With the explosion of mobile phones, browsers, and other IoT devices, building scalable and easily-maintainable automated UI tests has become more critical than ever over the past few years. The process has also never been more challenging. Brittle and unreliable tests can cause roadblocks in Agile and DevOps processes and impede the continuity of any CI/CD pipeline.
Testers today are all too familiar with the headaches caused by flaky tests. Any change made to the user interface (UI) or underlying code base of an application can cause automated tests to randomly fail. Especially those designed at the UI layer. This in turn means hours of maintenance overhead, slow feedback loops for developers and ultimately, a hindered testing cycle. Test flakiness is an issue every team runs into, and is often brushed aside or considered a natural phenomenon at low numbers. Cutting the number of flaky tests by even a tenth can provide astounding and positive test results that lead to a higher pass rates for tests a more streamlined testing cycle.
The number one problem in dealing with flaky tests is that it’s impossible to be rid of them entirely. The goal of this eBook is not to tell you how to eradicate flaky tests, but rather give you methodologies or practices that you can use to reduce the overall number. Budgeting time in your release planning sessions to analyze and fix flaky tests will lay the foundation for long term success.
Throughout this eBook, we will cover:
- The negative impact of flaky tests
- Top 4 reasons tests are flaky
- How to overcome the challenge of flaky tests
2. Hardcoded and Poor Test Data
Test data should work seamlessly with the design of the test. If tests work independently of each other, so should the test data, meaning it should be stored separately.
In the event a test is dependent on data from another tests, careful measures need to be taken to avoid corrupting the data during each test run to ensure the next test works properly. Test data needs to be valid at every point along the chain.
It’s also not uncommon to have poorly designed test data that doesn’t cover all the possible test or business scenarios. Testers often cover both the positive scenarios that come up and also the negative scenarios, but it is easy to forget these edge cases. It’s important to pay attention to these edge cases.
4. Underestimating Tech Complexities
Software applications today are rarely standalone products and depend on a network of subsystems to function properly. Many of these underlying systems and the processes they implement can be independent of the rest of the application.
This means they can complete the task they were built to accomplish without having to wait for feedback, making the application as a whole, asynchronous in nature. Testers have to take arising complexities like these into consideration as the tests they run will also be asynchronous.
Applications are often broken down into multiple components for testing and the testing process itself often consists of multiple tasks. In software development, tests that are synchronous can only be executed in a particular sequence, or only one step at a time.
- Call or update test data
- Run the data through a UI test
- Wait for a response
In this example, each task cannot start until the previous one has been completed. Asynchronous tasks can be triggered prior to the first one finishing. To combat this streamlined workflow, testers will put random timeouts in their tests, which often causes two problems:
- The time-out may not be long enough. If it isn’t, the UI test will break when the response isn’t long enough and you end up with a flaky test.
- Alternatively, you could have the opposite problem. If the time-out is too long, you could be waiting to get the right response and your tests will be slow.
How to Avoid Flaky Tests
Follow the Testing Pyramid
Correctly designing and driving tests at the UI layer should be done through encapsulation, or page objects. Imagine a website application with two form fields, A and B, that have some type of addition or multiplication logic applied.
| A | B |
|---|---|
| 4 | 5 |
When run, depending on the logic, you get different results.
| Addition | Multiplication |
|---|---|
| A | B |
| 9 | 20 |
The first way you might consider testing this functionality, is to validate the results (9 or 20) by driving the test at the UI layer. The automated test script you create could go to the website, drop in the values for you, and then click the multiply or add button. You would then compare the expected results with the actual results.
In this example, the moment you change the multiplication button or the expected value, the actual result will differ and your test would fail. The pass rate for this test would be atrocious as the test itself is overly dependent on other components.
The input value 4 interacts with both the multiplication button and the expected result. This type of dependency can be avoided by simply following the testing pyramid.
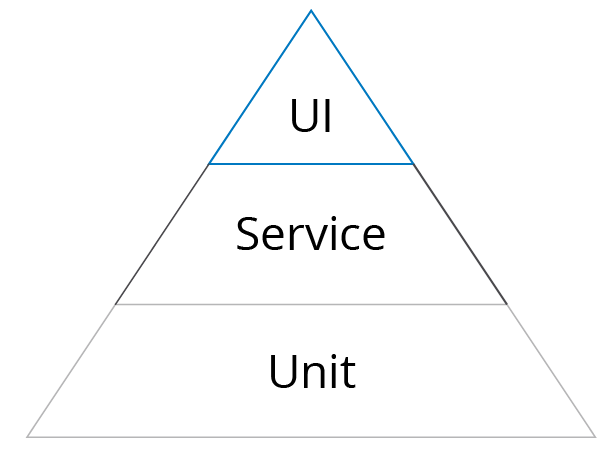
The largest number of any test type in a suite, automation or manual, should be unit tests. Unit testing is designed to test an application’s core functionally by breaking apart the software itself into bite-sized pieces. This could be an individual function, property, or method. Unit tests are the tests designed to validate each of these isolated components.
The UI of any application calls these underlying functions and methods on an ongoing basis. If the addition function from the previous problem can accurately portray that 4 + 5 is 9, and that 4 x 5 is 20, then the UI tests that are based off of this unit will be more resilient.
Following the structure of the pyramid, tests that are run through the service layer of the application should be next. These are your automated API or acceptance tests, which are used to test the business logic, such as inputs and outputs, without involving the UI layer. In our example, to test the service layer separately, you would test the multiplication and addition function separately from the GUI layer.
When finally testing the GUI layer, as mentioned previously, do so through UI encapsulation. The best way to think about this is how to implement page objects in the real world. Let’s use a familiar and albeit, over-used example, e-commerce. The basic action that drives all e-commerce platforms is adding an item to a shopping cart.
Now, what is the best way to test this action on the user interface? Breaking apart the ‘what’ from the ‘How.’
In the diagram below, note that there are the three different steps on the right that it takes to complete the action on the left. The key takeaway from this image is that it’s essential to separate the ‘what’ from the ‘how,’ or the action from its associated methods.
When a component on the UI layer is adjusted, the ‘what,’ will remain the same, but the steps to get there often changed. When this happens, the initial UI test will fail, but you can pinpoint which of the three methods needs to be addressed. It’s easier to make the change on one band than it is to adjust the entire UI test.
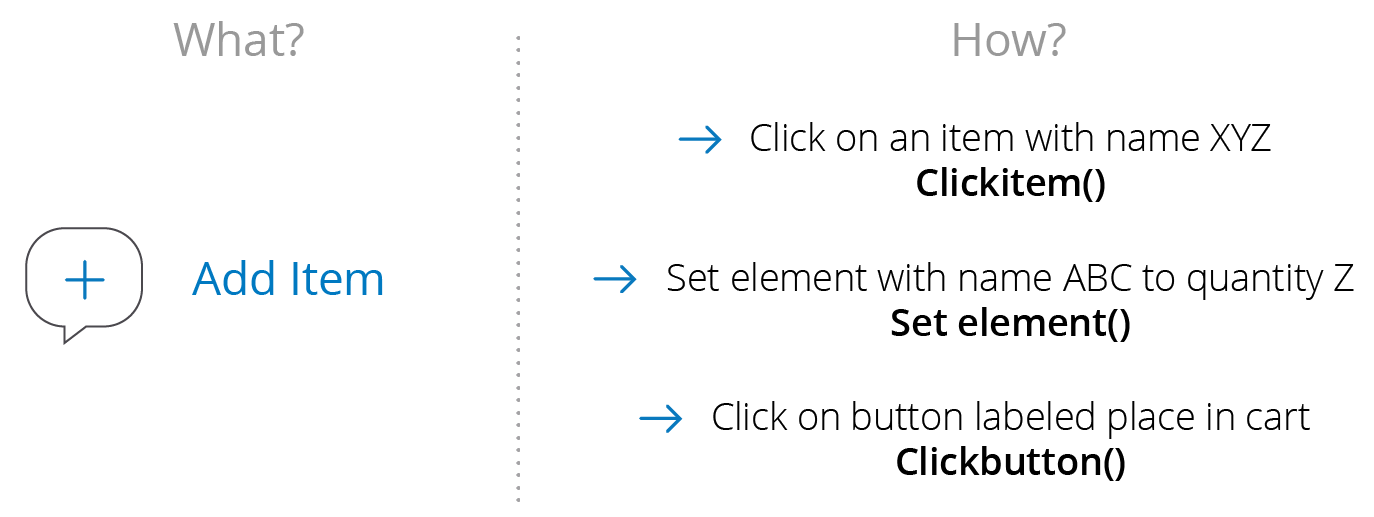
By decomposing the action into individual components, you can break down the UI workflow. Having this understanding is going to be the foundation for what you build up as you create a more thorough UI-based test suite.
Limit Your Dependency on Environments
Throughout this ebook, we reviewed a few different manners in which tests can talk to or interact with other systems. These interactions need to be limited. Tests should be segmented into groups based on whether they have an internal or external focus and their connections should be parameterized. It can be helpful to break the connections down into two pieces – what information you’re sending and what information you’re receiving.
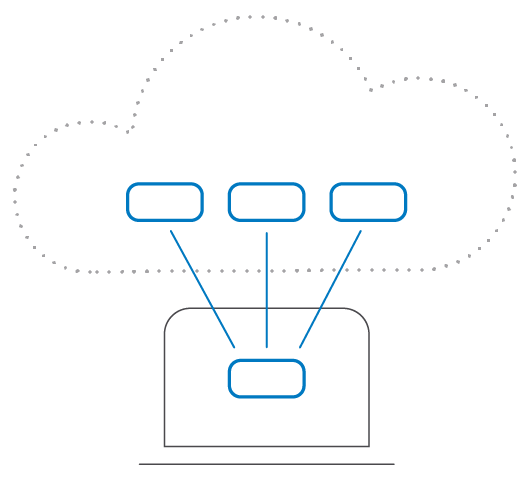
This will build what’s called an abstraction layer, which enables you to implement other testing practices, such hermetic servers. A hermetic server is basically a “server in the box.” Test communication is not limited to external systems as your application often engages with other pieces of itself. Hermetic servers that are entirely internal can be helpful in situations like this.
Rather than using an external system, with a hermetic server internal, you are using everything on your local machine. This means you can load your entire server on your machine and you don’t have to worry about sending a front-end request and getting a back-end response. This sets up a mock server on your machine, so you don’t have to set up a network connection and the server will work as expected – locally.
While It’s important to use hermetic servers as a solution, you also need to ensure you’re testing in real world cases as well for your own sanity. The three key steps you can take to limit your dependency on environments are:
- Limit calls to external systems
- Parameterize your connections
- Build a mocking server (however, there are still some downfalls when it comes to this…)
The key downfall across each of these is that they don’t simulate real world conditions. By this, we mean faking external dependencies. These are not real world experiences.
At the end of the day, you always need to focus on your end user experience, so it’s essential to maintain and clean up tests. We understand that this is not a real-world scenario.
Rather than cutting dependencies altogether, think of these as best practices for reducing dependencies. If a test is breaking and you can safely rule out as many components as possible that are working correctly by mocking them, the easier time you’ll have trying to figure out what is going wrong.
Measuring Test Stability
After addressing the four top issues behind flaky tests and ensuring you’ve cleaned up your acceptance test strategy by removing any remaining flaky tests, let’s say you’ve successfully knocked your failure rate down from 0.5% to 0.2%. Plug this back into the original calculation.
Test Suite Pass Rate = (99.8%)^ 300 = 54.84%
Your entire test suite pass rate has jumped up from 22.23% to 54.84%. In other words, an increase of 59.4%. Now, this is still less than 100% of your tests. What do you do next? Using just a little more math, you can estimate the frequency with which your entire test suite is going to succeed. In other words, you can measure your test stability.
Take each of the following four components:
- Sample Size (n)
- Desired Confidence (c)
- P Interval
- 1-P
Let’s say you have 50 test runs and a desired confidence interval of 95%, meaning you want to be 95% confident your test runs have the probability of passing. If only 29 out of 50 tests pass, this gives you a p value of .58, and inversely, a .42 for your 1-p value. You would then plug these numbers into the formulas below.
- Sample Size: 50
- Desired Confidence: 95% Confidence
- P Interval: 29/50 = .58
- 1-P: 21/50 = .42 or 1- .58 = .42

Where
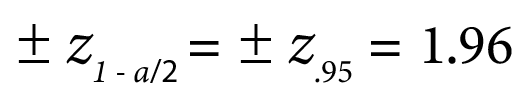
Using this formula, you can compute a binomial confidence interval to get an understanding of the proportion of tests that would pass in a target population. In this case, your test suite.
Step 1:

Step 2:
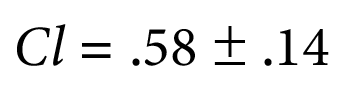
Step 3:
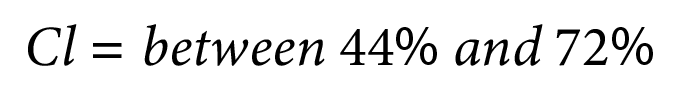
What this tells you, is that you can be 95% confident that the proportion of tests in the target population would pass between 44 to 72% of the time. Rather than just saying a number of 58%, we can get an idea of the population as a whole based on the information we get from this sample size.
Separate Test Data from Design
The most important practice you can implement to save time and headaches on test creation and maintenance is to separate test data from test design. One reason for this, is that it will enable you to run data sets through tests so you can run multiple scenarios and tests in parallel to speed up development and delivery cycles.
To separate test design from data, you have to limit the dependency between tests. Take three tests cases – A, B, and C. Test B depends on test A, and test C depends on test B. If test B turns out to be flaky and fails to create accurate data for test C, then test C would also fail.
If test A pulls inaccurate data, both tests B and C will fail. Storing data sets separately, via an excel spreadsheet or external database, will enable you to run all three tests independently and if issues do arise, you can figure out whether the problems arose from the test design or the data.
There are two types of test data you will interact with daily:
-
- Test Specific Data: This is data you will be validating at the end of an automated test. Going back to our ecommerce example in which you are buying a product on amazon.com, your test specific data would be ensuring the money that should be debited from your bank account has actually been debited. In this workflow, the test does not take who is using the amazon account into consideration, but only that the right amount of money is taken out of the account.
- Reference Data: This is the data that isn’t being validated while the test is running. In the ecommerce example, this could be items such as your name or address. You can see here, how having the right specific test data is important.
Each data type is accessed and leveraged differently. In the same manner you separate a test’s design, you should also separate and compartmentalize the test data.
There is data you use and data you check. When you’re using an external data storage system, you can conduct UI tests at a transaction layer and roll back the transaction to check that everything is okay. Data, and the databases they are stored in, should be considered an external system to your application.
It’s inevitable that data will have to be passed from one test to another at some point. In some workflows, it’s simply unavoidable. These tests will inherently always be somewhat flaky. The first step here should be to reduce the number of those tests and the second to ensure the rest of the tests in the suite are working as well as possible.
Removing Flaky Tests from Your Acceptance Test Build
After taking these four root causes – test design, data, environments, and tech complexities – into consideration, you will still have flaky tests. However, if UI tests are a part of your acceptance build, these should never be flaky.
Acceptance tests are designed to validate a system or application’s readiness for delivery. The key question answered by running acceptance tests which are designed to focus on usage scenarios is to determine whether the application under test meets business requirements or not.
If acceptance tests are failing frequently, they should not be a part of your acceptance build criteria. Combining flaky tests with healthy tests will give you the wrong feedback from your test suite, which will in turn limit how quickly and effectively developers can respond to any issues.
One of the biggest testing mistakes you can make that will limit the scalability of your DevOps and Agile movements is falling down the rabbit hole of being accustomed to acceptance tests failing.
Separating flaky tests from healthy tests will enable you to control the variables and provide a lens into where the problems with the tests lie. Bucketing your flaky tests doesn’t necessarily mean you can let the number continue to increase on a daily basis.
A best practice to follow here is to develop a good testing strategy that sets a limit on the number of flaky tests you can or are willing to have. Your strategy should also have restrictions on the amount of time a test can be kept in the ‘flaky’ bucket.
You do not want to increase your technical debt. The flaky test bucket should not be a final destination. It should be a transitionary point as you rework your tests to be even better in the event that you can. To avoid this, set the limit of tests you will allow in your flaky test bucket as well as the duration for each test.