Breaking Down the CrowdStrike Outage Part 2: Observability Strategies to Prevent Application Catastrophes
On July 19th, 2024, the world witnessed a large-scale computer outage caused by a faulty update from cybersecurity giant CrowdStrike. This incident, affecting millions of Windows devices globally, serves as a stark reminder of the domino effect that software errors can have. In part one of this series, we discussed the role QA methodologies can play in preventing future outages. Here, we’ll dive into observability – and how CrowdStrike could have avoided this situation by implementing progressive delivery and a robust monitoring strategy.
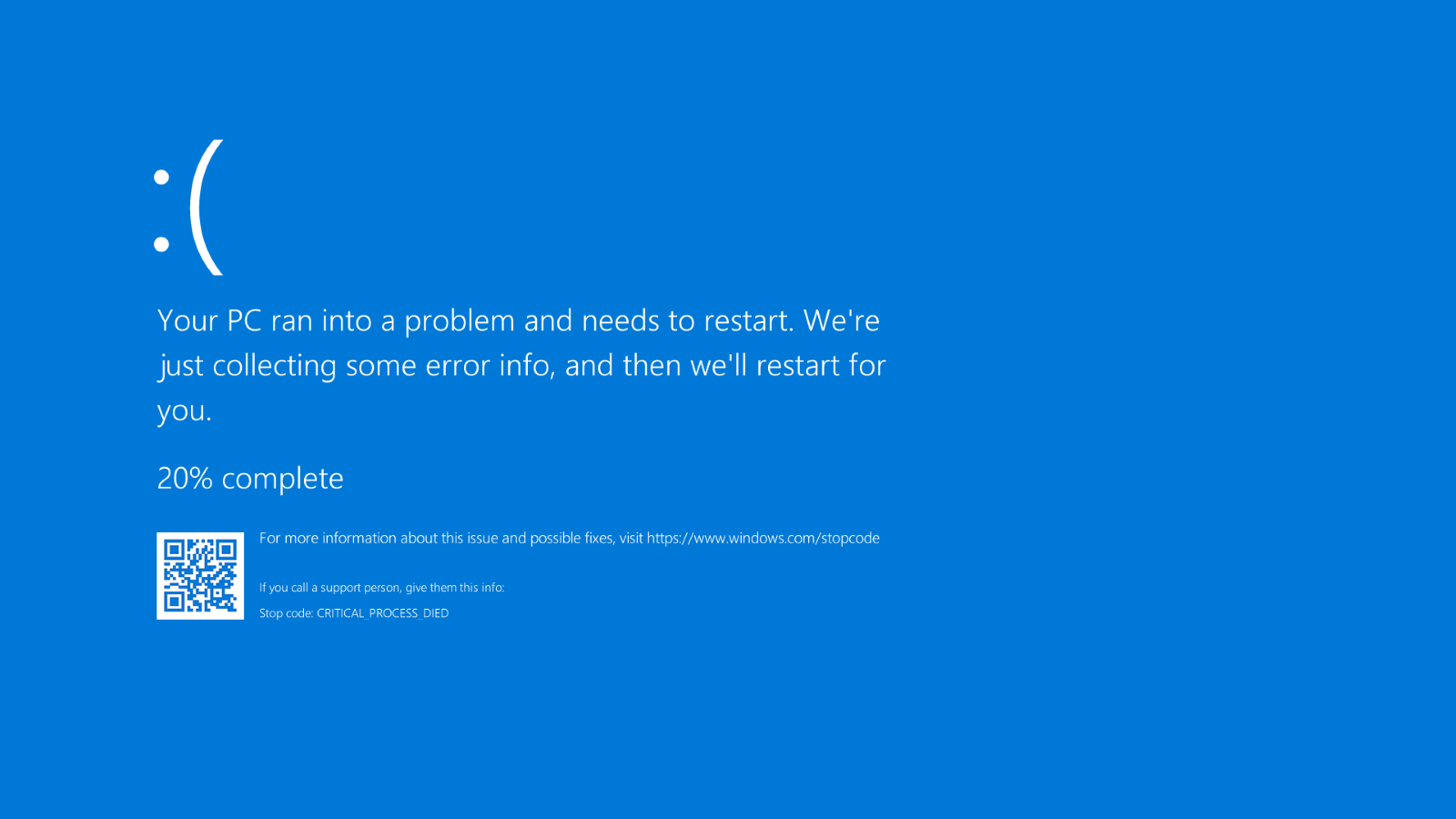
Microsoft’s infamous blue screen of death (BSOD).
What Caused the CrowdStrike Outage?
The culprit behind the outage was a seemingly innocuous update – a sensor configuration update for CrowdStrike’s Falcon antivirus software on Windows machines. Unfortunately, this update contained a logic error that triggered system crashes and the dreaded Blue Screen of Death (BSOD) upon activation.
The technical details, as explained by CrowdStrike themselves, point to a configuration update triggering a logic error. This error resulted in a system crash, causing affected devices to reboot repeatedly and become unusable.
Strategies that Could Prevent Similar Outages
Bugs and errors will always exist. The key is to mitigate the effects of potential errors by implementing strategies to prevent deployment with bugs (as much as possible) and quickly resolve them in production. That’s where a strong observability strategy comes into play.
Here are some observability strategies that could have helped CrowdStrike avoid this disaster:
- Progressive Delivery: Progressive delivery is a modern way of developing, testing, and deploying code, which allows development teams to make data-driven decisions throughout the SDLC, from pre-production to production. In short, it helps teams decide when to roll out or roll back releases, which could have quarantined the CrowdStrike issue to a smaller population.
- Proactive Error Monitoring: An effective observability tool would have identified unusual spikes in errors or system crashes coinciding with the CrowdStrike update deployment. This would have alerted engineering teams much faster, allowing them to isolate the issue and potentially prevent a wider outage.
- Detailed Error Reporting: In-depth error reports with clear stack traces would have quickly pinpointed the exact location of the error within the CrowdStrike update. This would have expedited troubleshooting and facilitated a quicker resolution.
- Real User Monitoring: Continuous monitoring helps maintain situational awareness of application health. By tracking real-time performance metrics, dev teams can proactively identify potential issues before they snowball into major outages.
The Importance of Release Management
Sometimes bugs make it past testing, and that’s okay if you have a strong release management process. This part of the SDLC ensures new updates meet their promised scope and each release is stable and won’t affect the integrity of the current production environment. This is part of practicing progressive delivery.
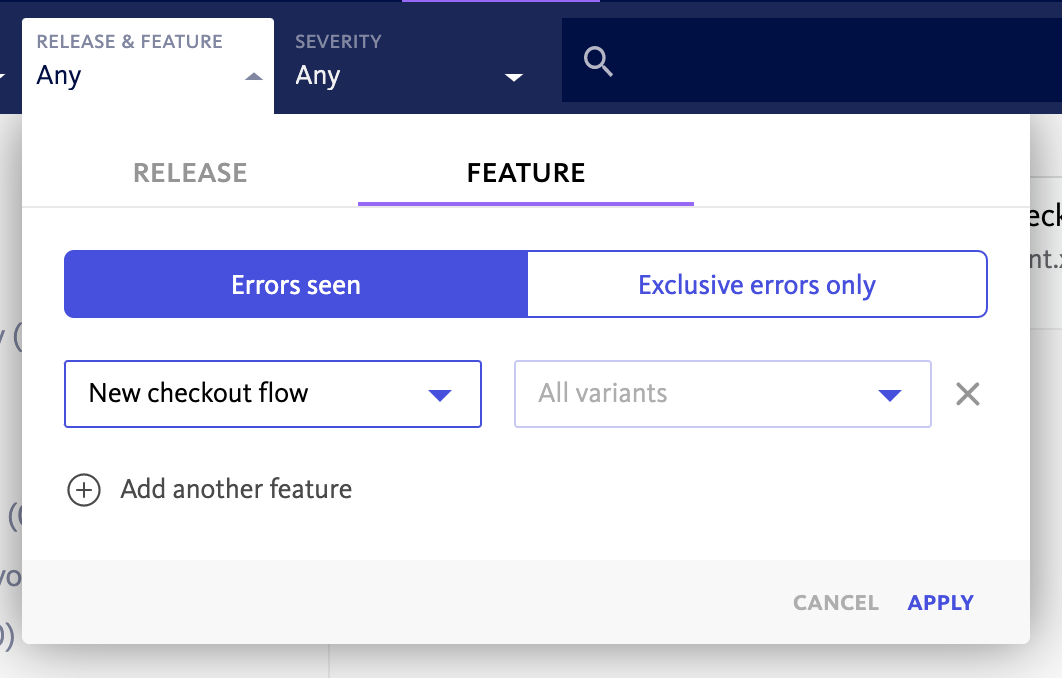
BugSnag allows developers to drill down to specific areas of their application so they can identify where errors are occurring.
Let’s explore how BugSnag can help teams maintain their application stability while rolling out new releases:
- Feature Flags and Experiments: Using BugSnag’s feature flags, developers can push new updates to a small group of users to assess if the update will affect the stability of the application or cause errors. This avoids updating the app for the entire user base, which can cause catastrophic issues like those faced by CrowdStrike.
- Features Dashboard: Sometimes just feature flagging isn’t enough – BugSnag’s features dashboard monitors errors impacting flagged releases and experiments that are already running. You can see exclusive errors that only occurred when a flag or experiment were active, exposing critical issues in new releases.
- Version Control and Rollbacks: BugSnag integrates with release control systems, enabling developers to easily revert to a previous, stable version of their update if necessary. This minimizes downtime and ensures business continuity – something the developers at CrowdStrike would have certainly appreciated.
- Improved Communication and Collaboration: It’s important that everyone is on the same page – BugSnag facilitates communication and collaboration between developers and teams within an organization. BugSnag’s data access API makes it easy to share stability scores across your organization, and you can implement custom rules to create automatic error assignment across teams.
How to Fix Critical Errors Quickly
The CrowdStrike outage underscores the critical role of proactive application monitoring in today’s software development landscape. Here’s how BugSnag can help teams implement a robust monitoring strategy to avoid critical errors hitting production:
- Real User Monitoring: Gain insights into application performance metrics such as response times, throughput, and resource utilization.
- Comprehensive Error Monitoring: Capture and analyze all types of errors and exceptions, from simple JavaScript errors to complex server-side crashes.
- Real-Time Error Alerts: BugSnag provides real-time alerts for errors and performance issues, notifying teams immediately after the system crashes. This swift notification allows for faster intervention and damage control.
- Detailed Error Reporting: BugSnag captures detailed error reports with comprehensive stack traces and breadcrumbs, pinpointing the exact cause of an error. This allows developers to understand and fix the issue faster.
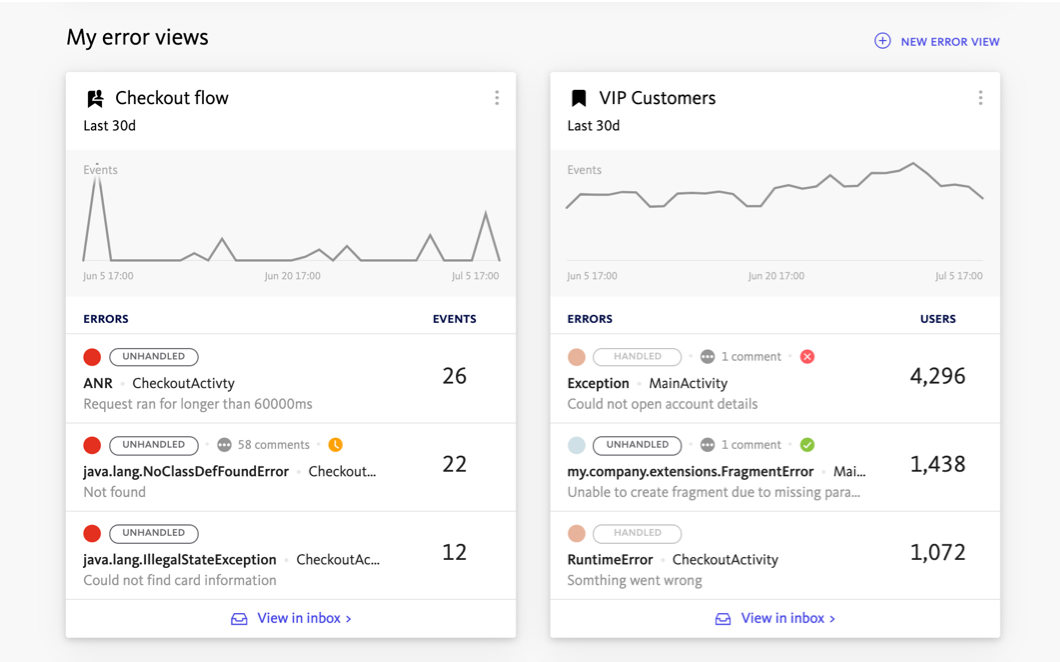
BugSnag allows developers to prioritize errors affecting the most important users and areas of their application.
By implementing an end-to-end, developer-focused error and performance monitoring solution like BugSnag, organizations can proactively find and fix issues well before they escalate into widespread outages. This not only minimizes downtime and financial losses but also safeguards brand reputation and user trust.
The CrowdStrike outage may be a recent event, but its lessons are timeless. Want to avoid something similar happening to your app? Learn more about how BugSnag can safeguard your app quality with error monitoring and performance monitoring. Try free for 14 days (no credit card required) or check out a demo.
Revisit Part One: Preventing Bugs from Reaching Production with QA Methodologies
Miss the first part in this series? In Part One we discussed the impact your QA practices can have on your release quality. No release is completely immune to bugs, but with the proper steps in place you will be able to shield your business from the most devastating ones.
This incident certainly exhibits the need for comprehensive testing and observability solutions. The more developers can connect across different stages in the software development lifecycle, the fewer opportunities for critical errors to occur. Overall, this kind of cross-functional collaboration allows developers to deliver high quality software.